背景
传统的 RDBMS 大多使用的行存储方式,现如今随着大数据技术的发展,对于存储的要求越来越高,列存储相对有自己明显的优势:列数据相对来说比较类似,压缩比更高;一般的查询只涉及几列,列存储的查询性能也更高;可以方便地新增列等。在某些场景下,选择列存储是非常不错的选择,从节省存储的角度来说就非常吸引人了。
目前,比较有名的开源实现有 Apache Parquet 和 Apache ORC。ORC 官网介绍 Facebook 和 Yahoo 都使用了 ORC。
本文主要简单介绍两种列存储的使用,并且有一个简单的测试结果,测试主要看数据压缩比,简单查询的性能对比,仅供参考。
Parquet
Apache Parquet 是 Apache 的顶级项目,是一个自描述语言无关的列存储,最初的设计动机是为了存储嵌套数据,可以将 ProtoBuf、Thrift、Avro 等格式的数据转换为列格式来存储,这是其最大的优势。此外,也有基本的功能,数据压缩、基本的索引功能、支持复杂类型等。主要在 Apache Drill 中使用。
从 Hive 0.13 开始,Hive 开始原生支持 Parquet,注意不是全部类型都支持,详情请参考 Hive 官方文档[参考8]。使用方法很简单,只需要在建表语句的时候,声明存储格式即可。
-- 建表,通过修改 parquet.compression 参数来修改压缩算法
CREATE TABLE parquet_test (
id int,
str string,
mp MAP<STRING,STRING>,
lst ARRAY<STRING>,
strct STRUCT<A:STRING,B:STRING>)
PARTITIONED BY (part string)
STORED AS PARQUET TBLPROPERTIES ("parquet.compression"="SNAPPY");
-- 数据迁移只需要将原来的表数据重新插入一遍即可
INSERT OVERWRITE TABLE parquet_test SELECT * FROM old_test;
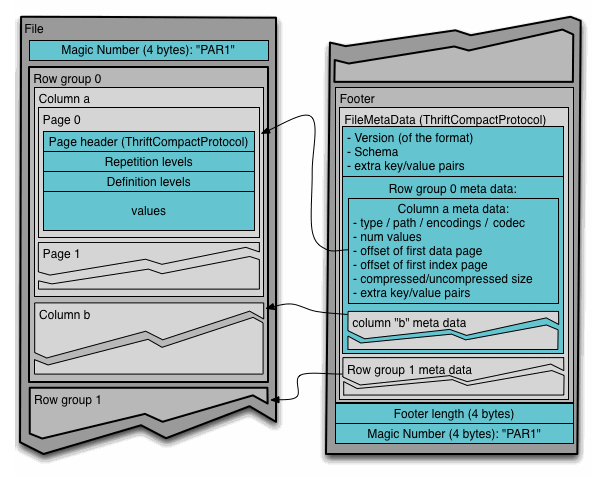
数据存储格式图
ORC
ORC(OptimizedRC File)也是 Apache 的顶级项目,也是自描述的列存储,源自于RC(RecordColumnar File),主要是在 Hive 中使用,支持数据压缩、索引功能、update 操作、ACID 操作、支持复杂类型等,其查询性能相对 Parquet 略有优势。
从 Hive 0.11 版本开始引入,使用方法也很简单。
CREATE TABLE ORC_test (
...
) STORED AS ORC TBLPROPERTIES ("orc.compress"="NONE");
-- merge small ORC files into a larger file, starting in hive 0.14
ALTER TABLE ORC_test PARTITION(...) CONCATENATE;
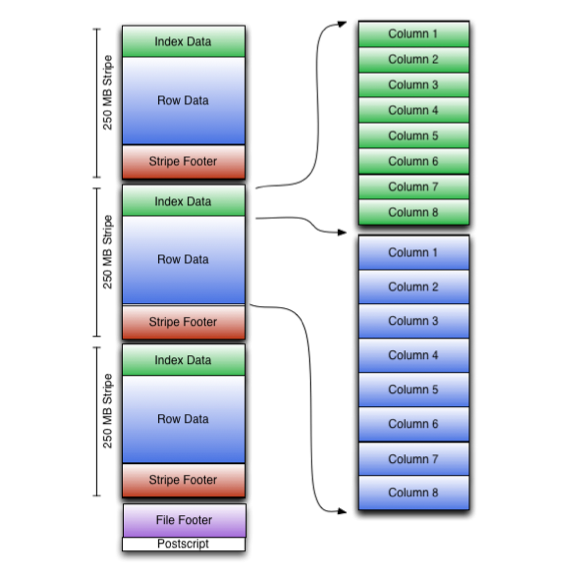
数据存储格式图
测试
下面的测试仅供参考,测试并不严谨,基本测试过程:建立对应格式的表,通过 SQL 将数据写入表中,查看文件大小,执行下面的测试 SQL。
-- 测试 SQL
select k1, sum(value) as num from test_table where k2 in ('a', 'b') and k3 = 'id' group by k1;
测试结果如下:
| Format | Compression | File Size | Cost Time | Cumulative CPU |
|---|---|---|---|---|
| textfile | NONE | 98.2 G | 41.521 seconds | 3745.67 seconds |
| ORC | ZLIB | 18.5 G | 31.713 seconds | 1107.44 seconds |
| ORC | SNAPPY | 28.0 G | 25.59 seconds | 1234.89 seconds |
| ORC | NONE | 87.6 G | 40.571 seconds | 1652.23 seconds |
| Parquet | NONE | 88.0 G | 33.318 seconds | 5440.49 seconds |
结论
根据二者的特点,根据数据的特点来进行技术选型:如果数据结构是比较扁平的,那么用 ORC 比较合适,如果嵌套较多,就用 Parquet。
列存储主要有两个好处:数据压缩和查询性能提升,在节省了存储的同时还提升了查询性能,这个的收益是非常可观的。

对于 Hadoop 来说,数据压缩是比较简单的,可以进行一些参数的设置来默认开启压缩,并且不需要明确指定压缩格式,在使用的时候会进行透明解压。
<!-- compression in mapred-site.xml -->
<property>
<name>mapreduce.map.output.compress</name>
<value>true</value>
</property>
<property>
<name>mapreduce.map.output.compress.codec</name>
<value>org.apache.hadoop.io.compress.SnappyCodec</value>
</property>
<property>
<name>mapreduce.output.fileoutputformat.compress</name>
<value>true</value>
</property>
<property>
<name>mapreduce.output.fileoutputformat.compress.codec</name>
<value>org.apache.hadoop.io.compress.GzipCodec</value>
</property>
Hive 也有相关参数可以配置。
<!-- compression in hive-site.xml -->
<property>
<name>hive.exec.compress.output</name>
<value>true</value>
<description>
This controls whether the final outputs of a query (to a local/HDFS file or a Hive table) is compressed.
The compression codec and other options are determined from Hadoop config variables mapred.output.compress*
</description>
</property>
<property>
<name>hive.exec.compress.intermediate</name>
<value>true</value>
<description>
This controls whether intermediate files produced by Hive between multiple map-reduce jobs are compressed.
The compression codec and other options are determined from Hadoop config variables mapred.output.compress*
</description>
</property>
<property>
<name>hive.intermediate.compression.codec</name>
<value>org.apache.hadoop.io.compress.SnappyCodec</value>
<description/>
</property>
<property>
<name>hive.intermediate.compression.type</name>
<value>BLOCK</value>
<description/>
</property>
压缩算法的 codec 默认也自带了多种,部分压缩算法(下面标有 native 的)需要其对应 C++ 的动态库才可以使用。
org.apache.hadoop.io.compress.DefaultCodec (native zlib,一般系统自带了)
org.apache.hadoop.io.compress.SnappyCodec (native snappy)
org.apache.hadoop.io.compress.GzipCodec
org.apache.hadoop.io.compress.BZip2Codec
org.apache.hadoop.io.compress.Lz4Codec (native lz4)
就压缩效果来看,在使用相同压缩算法的情况下,列存储的压缩效果略优于 textfile,基本还是在可以接受的范围内。但是 textfile 相对来说格式简单,数据的使用有比较大的灵活性,Hadoop 对数据压缩是透明的,可以自动解压数据,这个使用起来也非常方便。如果主要目的是为了节省存储,可以考虑 textfile 加上一个合适的压缩,这样也有非常好的收益。
