概述
LZ4 是一种常用的压缩算法,主要特点是压缩和解压的速度比较快,CPU 消耗低,移动设备上会用其作内存压缩的算法。
LZ4 算法的基本思想很简单,就是将数据中发现的重复项进行编码,达到压缩的目的。
本文仅仅介绍其算法的逻辑,不涉及具体的实现。
算法简介
对数据的重复项进行编码,编码的方式是 (offset, length)。
需要注意的是 offset 的含义有点特殊,用于计算在已经解码字符串中的重复项起始位置,起始位置 = 已经解码字符串的长度 - offset。
下面通过一个例子来简单说明其基本流程:
压缩前:abcde_bcdefgh_abcdefghxxxxxxx
压缩后:abcde_(5,4)fgh_(14,5)fghxxxxxxx
注意:这里使用的是一种逻辑上的格式,实际存储的格式需要参考下面的 Sequence 格式。
通过观察这里压缩后的数据,我们可以发现,起始压缩后的数据有两种:literal 和 match,也就是原始字符串和匹配项,匹配项的格式为(offset,length)。
接下来,我们通过解码流程,来理解压缩后的数据含义: 说明:
- 下面每步的开头都有一个当前的信息(已经解码字符串,offset,length),已经解码字符串为上一步的结果
- 对于 literal 的字符串是无需解码,直接输出即可
解码步骤:
- (“abcde_”, 5, 4):这里已经解码的字符串长度为 6,计算(5,4)匹配项的起始位置 = 已经解码字符串的长度 - offset = 6 - 5 = 1,长度为 4,匹配项为 bcde
- (“abcde_bcdefgh_”, 14, 5):这里已经解码的字符串长度为 14,计算(5,4)匹配项的起始位置 = 14 - 14 = 0,长度为 5,匹配项为 abcde
- (“abcde_bcdefgh_abcdefghxxxxxxx”, x, x),到达字符串结尾,解码完成。
最终得到解码的字符串为”abcde_bcdefgh_abcdefghxxxxxxx”,与压缩前的字符串一致。
这里是逻辑上的格式,物理上是由一个个 sequence 组成的 block,也就是 sequence 是 lz4 压缩数据的最小单元。下面我们就来深入研究下 Sequence 格式。
Linear small-integer code (LSIC)
在看 sequence 格式之前,先介绍一个 integer 编码方式 LSIC。
首先,读取一个 byte,将其累加到 n 中,如果该 byte 的值为 0xFF,也就是255,那么再继续读取一个 byte,并将其值累加到 n 中,直到读取到一个 byte 不为 0xFF,最终累加出来的 n 就是我们读取到的整数。
其读取逻辑如下:

这个编码方式也算是整数的压缩方法,假设大部分情况下使用的 integer 都比较小。
在 Sequence 格式中,literal 和 match 部分的长度使用了 LSIC 这种编码方式,只是第一个读取的数据从一个 byte,变为了 4 个 bit(半个byte)。
Sequence 格式
Sequence 的格式如下图所示:
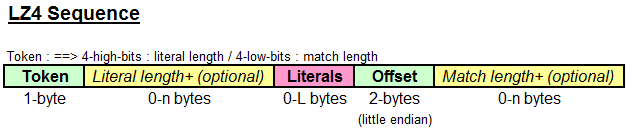
字段说明:
- token(1 bytes,required):前 4 bit 表示 literal 序列长度,后 4 bit 表示匹配序列长度
- LSIC编码:上图中黄色的部分(literal length+(optional), match length+(optional),就是在 4 bit 为 0xF 时(也就是,需要额外读取这个字段,其他时候是没有这两个 optional 字段的
- 匹配序列长度:这个长度需要额外加上 match 最小长度,这个值为 4(至于为什么,我们后面讨论)
- literals(optional):保存 literal 字符串,未压缩编码的部分
- offset(2 bytes,required):这个 offset 的含义与一般的略有不同,是一个逆向的 offset,表示匹配项的 offset,可以计算匹配项的起始位置,公式:匹配项的起始位置 = 已经解码字符串的长度 - offset
为什么最小匹配长度是4?
通过上面的 sequence 格式,我们可以看到 token 和 offset 两个是必选的字段,这个是为了压缩额外增加的 bytes,这两个加起来已经是 3 个 bytes,如果重复项 <= 3,那就没有压缩效果了,所以最小的匹配长度一定要大于 3,也就是 4。
这就是从 Sequence 结构上分析出为什么最小匹配长度是 4。
特别注意:在计算匹配长度的时候,一定要把这个最小匹配长度加上,每个 sequence 默认必须有 4 个及以上的匹配长度。
这是因为,既然最小匹配长度是4,那么所有的匹配长度都是大于等于 4,所以 4 就可以通过编码方式省下来。
那么 token 的后 4bit 最大可以存 15,再加上最小匹配长度 4,就变为 19 了,小于 19 的匹配长度都不需要额外的 match length+ 这个字段。如果不使用这个方式的话,那么只有小于 15 的匹配长度不需要额外的 match length+。
压缩上能省一点算一点吧。
示例分析
还是拿上文的例子
# 压缩前:abcde_bcdefgh_abcdefghxxxxxxx
# 压缩后 hex 表示:6061626364655f0500416667685f0e00a066676878787878787878
# 压缩后字符串打印:`abcde_Afgh_�fghxxxxxxx
这里是分为3个sequence,下面逐个来看,下面采用 sequence 的格式来说明。
说明:有两个字段是可选的,literal length+ 和 match length+,刚好这个示例字符串比较短,这两个字段均为空。
第一个:
| token | literal length+ | literal | offset | match length+ |
|---|---|---|---|---|
| 60 | 61 62 63 64 65 5f | 05 00 | ||
| abcde_ | 5 |
- 逻辑格式:abcde_(5, 4)
- token:60,表示6个 literal string,0表示 0+4,4个 match 长度
- offset: 0500 是小端 offset,也就是5
第二个:
| token | literal length+ | literal | offset | match length+ |
|---|---|---|---|---|
| 41 | 66 67 68 5f | 0e 00 | ||
| fgh_ | 14 |
- 逻辑格式:fgh_(14, 5)
- token:41,表示 4 个 literal string,1表示1+4,5个 match 长度
- offset: 0300 是小端 offset,也就是 14
第三个:
| token | literal length+ | literal | offset | match length+ |
|---|---|---|---|---|
| a0 | 66 67 68 78 78 78 78 78 78 78 | |||
| fghxxxxxxx |
- 逻辑格式:fghxxxxxxx
- token:a0,表示 10 个 literal string,0表示0+4,4个 match 长度,但是因为已经结束了,所以这里的 match 就会直接忽略掉,因为 lz4 的结尾肯定都是 literal
其他要注意的点
- lz4 的解码算法需要预先知道未压缩前的大小,因为他这里结束的时候是根据已经解码的字符串长度。
- lz4 解码的实现中,是可以去覆盖解码字符串中未被初始化的位置,在后续的解码中会覆盖掉。例如,直接按 8 字节批量进行拷贝,为了批量进行操作,提升解压效率。
- lz4 编码的过程中,可以进行更多更好的匹配,也可以进行简单的匹配,会导致最终的压缩率存在一定的区别,但是格式上依然保持兼容。例如,airlift compressor 的 Lz4Compressor 实现就只匹配从开头开始的字符串,而不会匹配中间匹配的字符串,这样来提升压缩速度。
