概述
2022年,Databricks 发布了 Photon —— 兼容 Spark 的 Native 引擎,并且还发布一篇 paper。photon 在英文中是光子的意思,所以显而易见的 Photon 的特点就是追求更快的速度。
其实早在 2020 年,Databricks 的 Reynold Xin 就在 Spark + AI Summit 2020 上介绍过 DeltaEngine,这个应该就是 Photon 的前身。
Photon 的实现方式是使用 JNI 的方式,在现有的 spark runtime 基础上单独开发了一套 native engine 的计算逻辑。因为 photon 并没有支持 Spark 所有的计算特性,所以 photon 和 spark 会各自执行部分计算。在 Databricks 的产品介绍上,会分为两个 Runtime:Databricks Runtime、Photon Runtime。
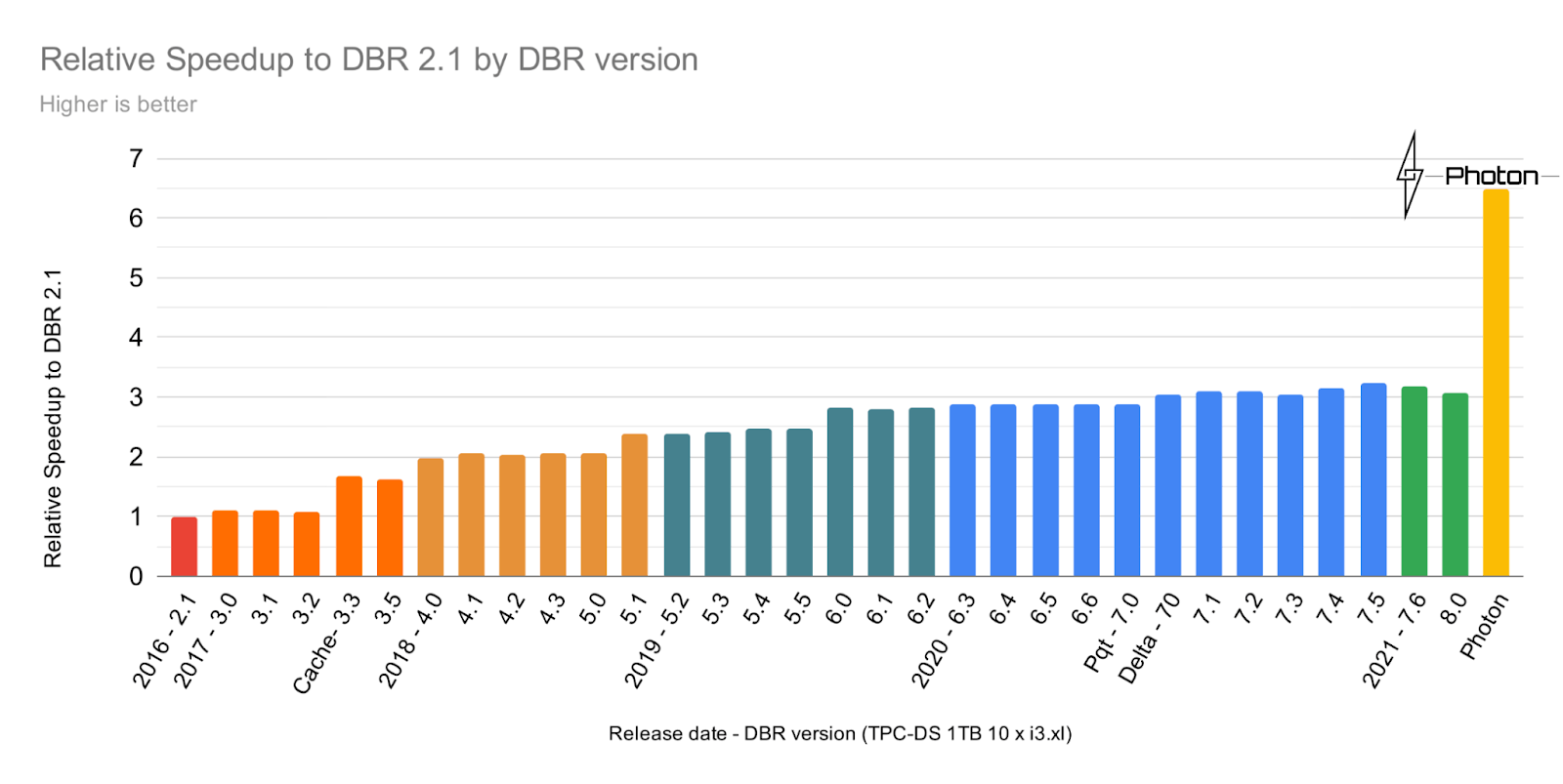
Photon 的开发用了两年多的时间,整体的性能提升的幅度就和之前 Spark 调优多年的性能提升差不多了,这是 Photon 项目取得的最大成功。(图片来自于Databricks PR blog)
Photon 目前并未开源,但是 Data + AI Summit 2022 上有一个类似的项目Gluten做了一个talk,由 intel 和 kyligence 共同开发的。这也是值得后续关注的一个项目,但是 intel 做这类项目很可能会半途而废,目前代码算是半成品,依赖的开源项目都进行了一些定制开发,后续可持续发展上需要重点关注下。
本文主要根据笔者个人阅读 Photon 论文和其他资料,谈谈对 Photon 一些粗浅的理解。
背景
databricks 目前主要是数据湖的架构 lakehouse,在使用 lakehouse 之后发现了一些新的挑战。
相较于传统的 OLAP 场景,lakehouse 查询的数据来源会更加多样。比较明显的问题就是会包含有较多的原始非结构化数据,其中一个特征就是大量的字符串。在非结构数据上也能有个不错的查询性能,就变成了一个比较合理的需求。
Spark 主要依赖 whole stage codegen 的方式,调试和优化的难度很大,并且还受到 JVM 的限制(例如 method 大小等)。在 JVM 上的优化难度越来越大,需要对 JVM 有非常深入的了解,这些都不利于后续的持续优化迭代。
所以,如果把目光投向 C++。我们可以发现至少有两大好处:
- 在字符串的处理上 C++ 会比 Java 的性能更加好,对于非结构化数据来说是有很大的优势
- C++ 代码的性能上比 Java 更容易预测,没有 JVM JIT 等的干扰,并且可以更容易使用 SIMD 指令,自行进行内存的管理
在确定了 C++ 开发 native engine 的 Photon 之后,有一个比较大的变化:对于 spark 的计划来说,原先的 whole stage codegen 被打破了,因为 photon 和 spark 的算子是混合在一个 stage 上的,这样就无法整体进行 codegen。这样,就需要依赖向量化来弥补这部分的性能。
对于 Photon 来说,有个非常大的挑战:Photon 算子如何与现有的 Spark 进行整合,才能完美地兼容现有的 Spark API。
关于内存管理的额外说明,笔者进行过测试,JNI 中 C++ 创建的内存是不受 JVM 的堆外内存大小限制的,所以 JNI C++ 中管理内存是更加灵活的,也可以使用到更多的内存。
整体架构
photon 与 spark 会存在同一个 stage 中,photon task 也是单线程处理单个 partition 的数据,这个与 spark task 是一样的。整体的架构如下图所示:
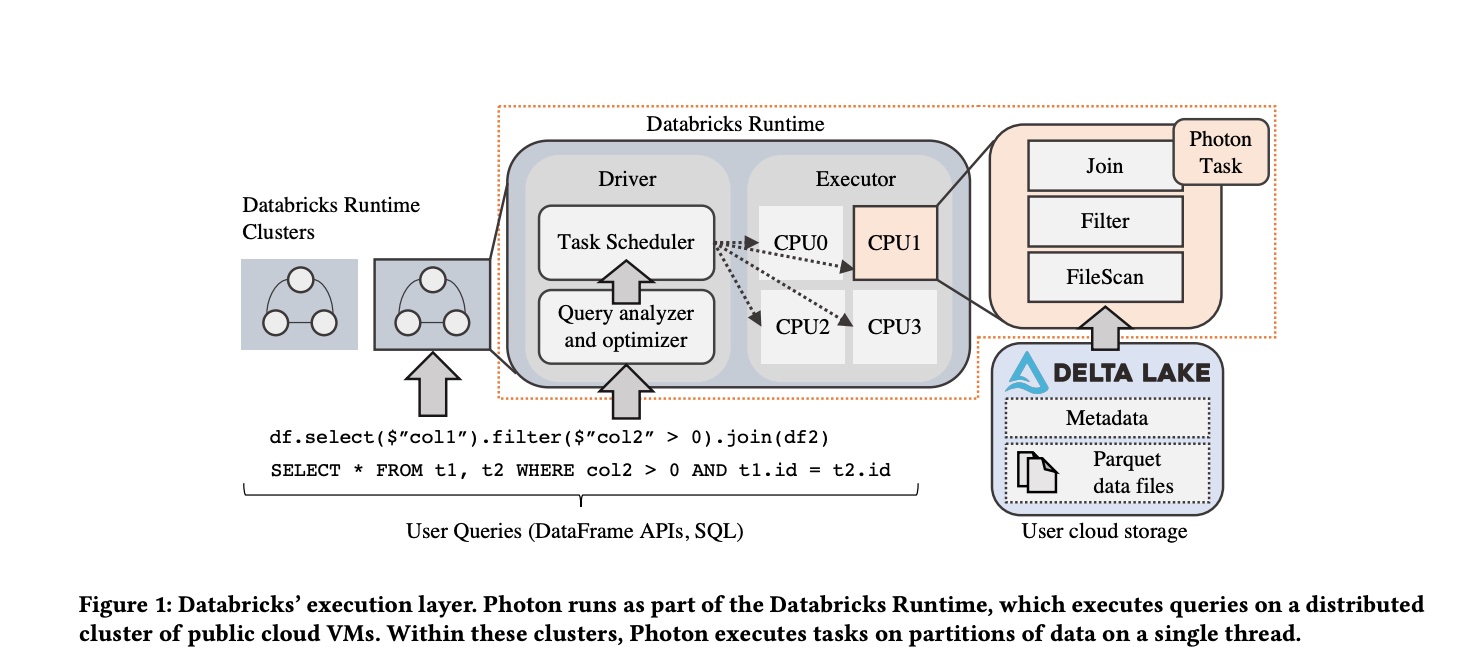
计划的整合上需要考虑 Photon 与 Spark 算子的边界如何处理,所以引入了两个算子:
- Adaptor:将从 FileScan 读取的数据直接传给 Photon 算子
- Transition:将 Photon 计算的结果传给 Spark 算子
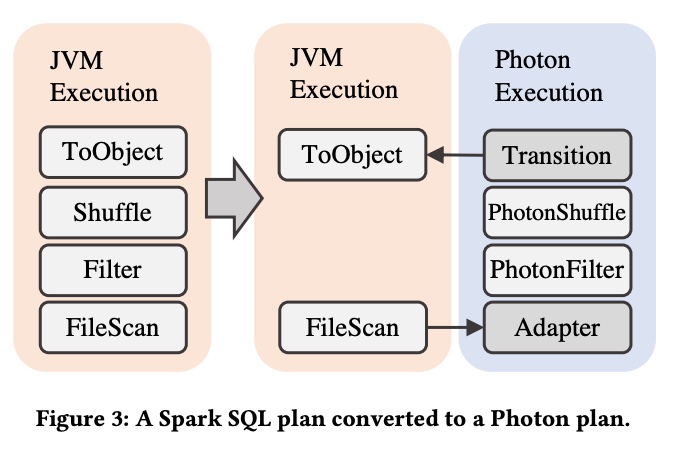
Photon 与 Spark 还有一个非常大的区别:Photon 是一个列存格式的计算引擎,Spark 是一个行存格式的计算引擎。
在 databricks 的 lakehouse 场景下,读取的都是 parquet 文件,parquet 是列存格式的,所以在原先的 Spark 中就存在一次 ColumnToRow 的转换。
在引入 Photon 后,可以直接从 parquet 读取数据,保持为列存格式直接在 Photon 算子中进行计算,只有在 Photon 到 Spark 算子的时候,再进行 ColumnToRow 的转换,这样仍然是一次转换。Photon 直接列存进行计算,更容易进行向量化。
整体的计划大致如下:
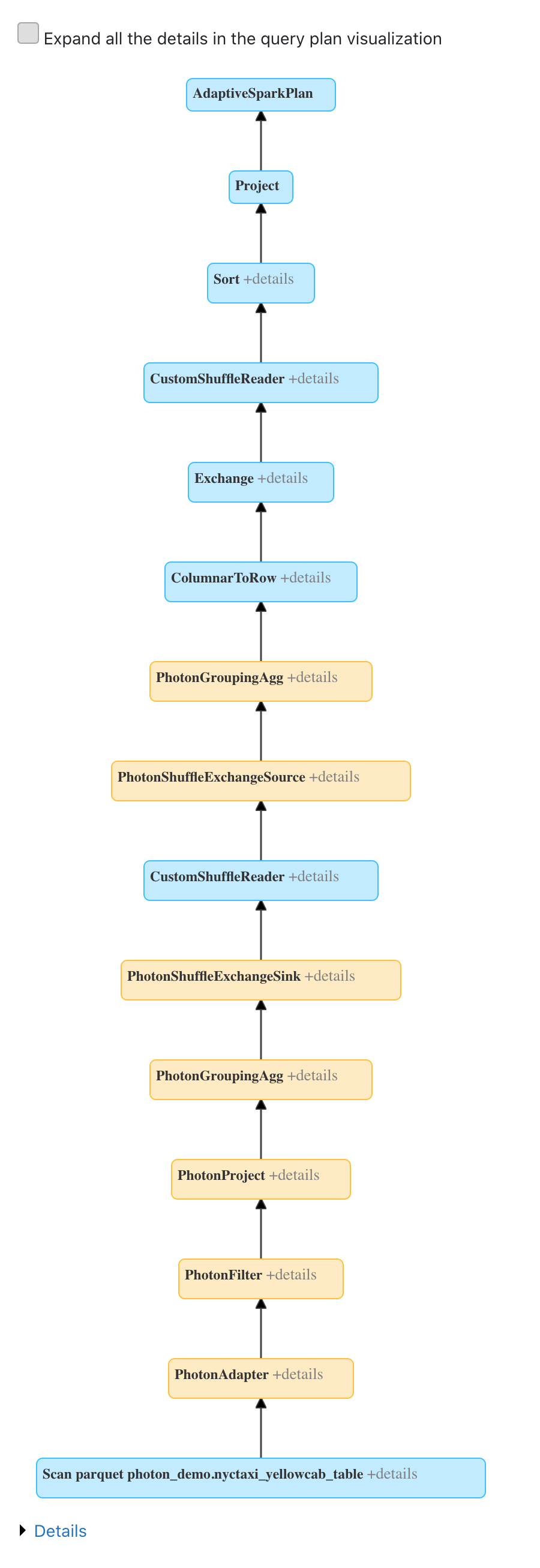
因为 spark 与 photon 之间的转换是存在比较大的开销,所以目前对 Photon 算子的使用方法是比较保守的,就是从读取数据的源头 FileScan 开始,尽量使用 Photon 进行计算,在碰到不支持的计算后转换为 Spark,转换为 Spark 后不会再转换为 Photon。这样可以保证对 Photon 的使用都是有正向的收益。以后,可以考虑计算 Cost 来选择是否使用 Photon。
额外说明:对于本身计算引擎就是列存格式的来说,就不会有这一次 ColumnToRow 的转换,那么就需要考虑 JNI 数据传输的开销,也就是从 C++ 把数据传递给 Java 的序列化开销。Photon 可以将这个开销合并在 ColumnToRow 的转换中,转换后的内存直接写到 Java 侧。
统一内存管理
Photon 和 Spark 是属于部署在相同节点上的,所以也共享了内存和磁盘,需要全局的内存/磁盘资源管理。Photon 直接使用了 Spark memory manager,来达到全局统一的管理。
内存管理上的特殊之处在于,Photon 区分了 allocation 和 reservation:
- reservation:需要从 spark unified memory manager 中申请需要的quota
- allocation:在申请完 quota 后,Photon 就可以直接申请内存,也不会进行 spilling,这里的内存只是在 Spark 中进行quota使用的记录
内存不足时的 spill,内存释放逻辑:
- spark 的逻辑:在向 spark memory manager 申请内存的时候,内存不足的时候会让 spark memory consumer 释放内存,来满足新的申请要求
- photon 的逻辑:Photon 实现了 spark memory consumer,所以 spark memory manager 也可以让photon来释放内存
计算优化
Photon 使用了 Execution Kernels 来进行向量化的优化(这个是受到 MonetDB/X100 的启发)。通过这些基础的 kernel 的实现,然后可以再组合成更为复杂的计算逻辑。
向量化的部分在论文中提到还是主要以编译器来自动向量化为主,依赖编译的自动向量化需要开启 O3 的优化,目前自动向量化的效果还是挺好的,比起直接使用 SIMD 指令代码更加简单好维护。
关于向量化和 codegen 的技术选型上,论文中提到使用 Weld 作为 codegen prototype 实现,与向量化进行对比后,最终选择了向量化的路线。向量化的优点如下:
- 易于开发调试,方便后续扩展
- 计算的指标监控容易获取,codegen 会涉及多个计算融合成一份代码,指标不好统计
- 根据每批数据(batch)的特征,进行适配,codegen 会涉及到 recompile 的开销,向量化则没有这个开销
Adapative Execution 是 batch 粒度的,这里以 batch 中是否包含 null 为例。
通过 template 的方式来去针对是否包含 null 进行优化,对于没有 null 的情况,就少了一次分支判断。因为是 batch 粒度的,所以只要局部的 batch 没有null,就可以使用这个没有 null 的版本,这样就可以得到性能上的提升。
template <bool kHasNulls, bool kAllRowsActive>
void SquareRootKernel(const int16_t* RESTRICT pos_list,
int num_rows, const double* RESTRICT input,
const int8_t* RESTRICT nulls, double* RESTRICT result) {
for (int i = 0; i < num_rows; i++) {
// branch compiles away since condition is
// compile-time constant.
int row_idx = kAllRowsActive ? i : pos_list[i];
if (!kHasNulls || !nulls[row_idx]) {
result[row_idx] = sqrt(input[row_idx]);
}
}
}
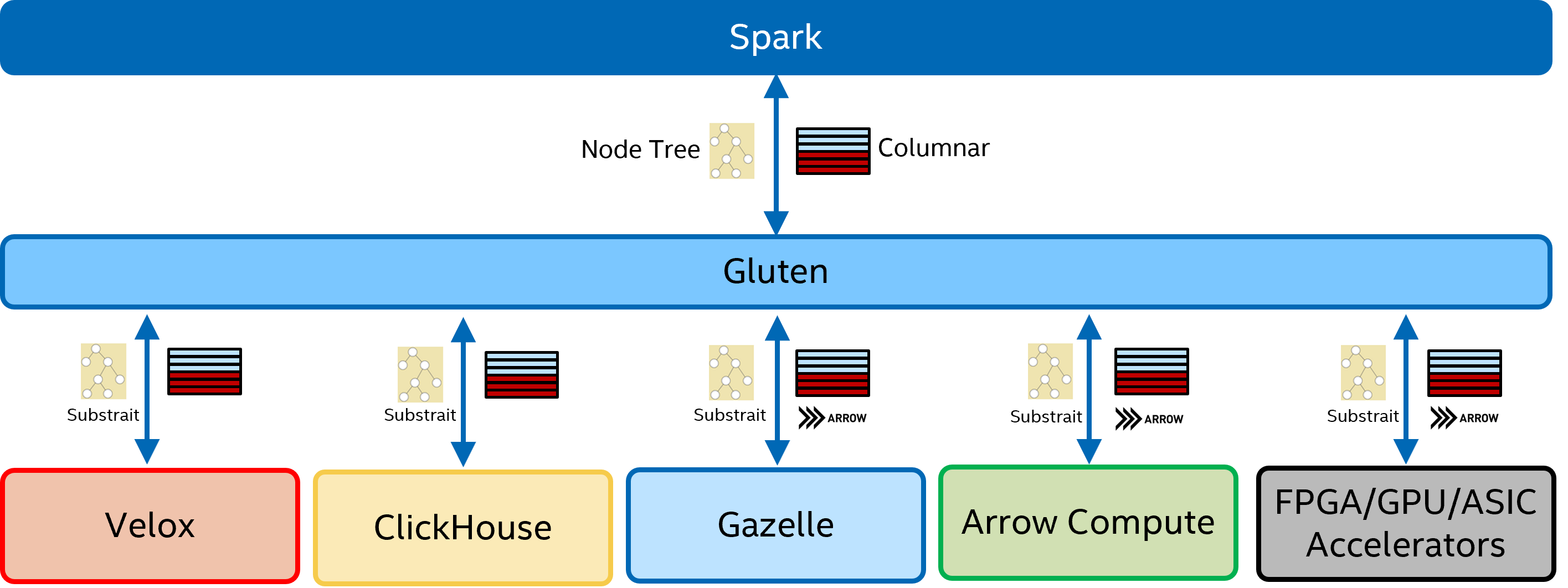
Gluten
Gluten 是目前与 Photon 定位类似的,并且目前处于开源状态,开发者基本都来自国内,有一些比较重要的参考意义。
Gluten 定位是一个 Spark 的 native engine 中间层,底层可以对接多种 native engine,例如 velox、clickhouse、arrow 等。目前支持的状态时 velox 和 clickhouse 相对完善一些,可以初步跑通 TPCH。
数据传输和格式都是使用了 arrow 格式,计划使用了 substrait 格式,spark 的计划会转换为 substrait 格式,然后再传递到下层的 native engine中。
整体架构如下:
总结
在大数据的初期,优化的方式都是移动计算,而不是移动数据。近些年,随着网络带宽的快速发展和云原生等场景对于存储计算分离的需求,逐步倾向于移动数据,网络传输数据的速度也越来越快,计算引擎的性能瓶颈从网络io重新转回到了CPU上,所以才会出现越来越多的 native engine,来进一步压榨 CPU 的性能。
Photon 是这一大背景下的产物,C++ native engine 是当前 OLAP 的一个主流趋势,也是未来计算引擎的发展方向。
参考资料
- Photon: A Fast Query Engine for Lakehouse Systems
- Announcing Photon Public Preview: The Next Generation Query Engine on the Databricks Lakehouse Platform
- Photon Technical Deep Dive: How to Think Vectorized
- Gazelle-Jni: A Middle Layer to Offload Spark SQL to Native Engines for Execution Acceleration (Gluten)
- Gluten github repo
- Databricks Photon尝鲜
- Delta Engine: High Performance Query Engine for Delta Lake
