概述
LRU 是 Least Recently Used 的缩写,意思是最近最少使用,是一种常见的缓存淘汰策略,其他策略还有 FIFO、LFU 等。缓存的访问速度比较快,但是其是一种有限的资源,所以需要进行缓存的淘汰,一般情况下缓存会使用内存,计算机的内存一般来说都有比较有限的资源。
下面通过一个示意图来解释 LRU 的整体过程。
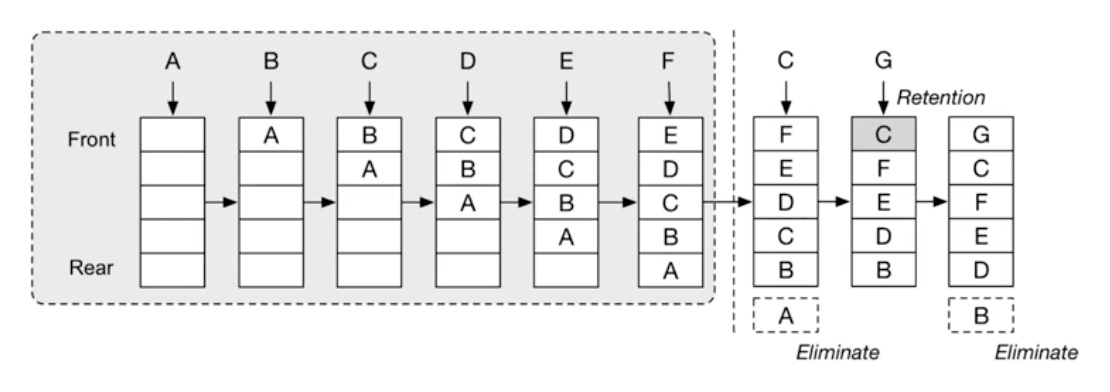
如上图所示:
- 一个 capacity 为 5 的 LRU cache,前面五个元素 A、B、C、D、E 填充满 cache
- 第六个元素 F 添加到队尾后,最早加入的 A 元素被淘汰,即队头被删除
- 再次访问元素 C,那么 C 的新鲜度被刷新,重新添加到队尾
- 第七个元素 G 添加到队尾后,队头的 B 被淘汰
说明:这里的说明是以上面为队尾,下面为队头。反过来,上面是队头,下面是队尾也可以。
基本操作定义
LRU 主要包含两个操作:put 和 get:
- put(key, value):插入新的 key value 数据,当数据条数超过阈值的时候,进行淘汰
- get(key):读取指定 key 的数据,不存在的时候返回 -1 或 NULL
实现方法
这里的实现还是以 leetcode 146 为例,可以通过是否 AC 来检查代码编写是否正确。
[C++] map + double linked list
首先,需要思考使用什么数据结构:
- 因为是 cache,所以首先想到哈希表,对于 C++ 来说就是使用 unordered_map
- 难点是如何识别最近访问的节点,为了方便把最近使用过的节点添加到队尾,淘汰的时候直接删除队头即可,可以联想到使用双端链表
确定数据结构后,整体的流程是怎样的?
- 对于 get、put 访问或更新过的 key,将其节点放入到队尾,队尾是最近使用过的节点
- 队头就是最久使用过的节点,淘汰的时候就可以直接淘汰队头的节点
示例代码如下:
struct Node {
int val = -1;
int key = -1;
Node* prev = nullptr;
Node* next = nullptr;
};
class LRUCache {
public:
LRUCache(int capacity) : capacity_(capacity) {
m.reserve(capacity_);
// dummy head 和 tail,用于简化双向链表的操作
head = new Node;
tail = new Node;
head->next = tail;
tail->prev = head;
}
int get(int key) {
if (m.find(key) == m.end()) {
return -1;
}
Node* node = m[key];
// 新访问过的节点,移动到 tail
moveToTail(node);
return node->val;
}
void put(int key, int value) {
if (m.find(key) == m.end()) {
Node* node = new Node;
node->key = key;
node->val = value;
m[key] = node;
// 新增节点,添加到 tail
addToTail(node);
// 容量检查
if (m.size() > capacity_) {
// 删除 head 端最旧的节点
Node* node = head->next;
removeNode(node);
m.erase(node->key);
delete node;
}
} else {
Node* node = m[key];
node->val = value;
// 新更新过的节点,移动到 tail
moveToTail(node);
}
}
void addToTail(Node* node) {
Node* prev = tail->prev;
prev->next = node;
node->prev = prev;
node->next = tail;
tail->prev = node;
}
void removeNode(Node* node) {
Node* prev = node->prev;
Node* next = node->next;
prev->next = next;
next->prev = prev;
}
// 移动到 tail 是分两步:删除节点,然后添加到 tail
void moveToTail(Node* node) {
removeNode(node);
addToTail(node);
}
private:
unordered_map<int, Node*> m;
int capacity_{0};
Node* head;
Node* tail;
};
其他
对于 Python 来说,可以直接使用 OrderedDict。而对于 Java 来说,可以直接使用 LinkedHashMap 来实现。详情参考leetcode 官方题解。
附录
Leetcode 官方题解的代码,拷贝到附录作为参考。
[Python] OrderedDict
Python 3.2 开始为 OrderedDict 添加了 move_to_end 方法,可以方便地把key移动到队尾或者对头(last=False),官方文档也添加了 LRU cache 的一些示例代码(LastUpdatedOrderedDict、TimeBoundedLRU、MultiHitLRUCache)。
class LRUCache(collections.OrderedDict):
def __init__(self, capacity: int):
super().__init__()
self.capacity = capacity
def get(self, key: int) -> int:
if key not in self:
return -1
self.move_to_end(key)
return self[key]
def put(self, key: int, value: int) -> None:
if key in self:
self.move_to_end(key)
self[key] = value
if len(self) > self.capacity:
self.popitem(last=False)
[Java] LinkedHashMap
LinkedHashMap 官方文档明确说非常适合做LRU:
- 使用构造函数
public LinkedHashMap(int initialCapacity, float loadFactor, boolean accessOrder),遍历顺序:from least-recently accessed to most-recently (access-order),正好符合 LRU 的语义 - removeEldestEntry(Map.Entry) 需要重载来实现删除逻辑
唯一与 LRU 的区别是:默认的 capacity 是 initial capacity,后续是可以容纳更多的数据,为了实现 capacity 是固定的,所以重载 removeEldestEntry 方法,当超出 capacity 后进行淘汰。
class LRUCache extends LinkedHashMap<Integer, Integer> {
private int capacity;
public LRUCache(int capacity) {
super(capacity, 0.75F, true);
this.capacity = capacity;
}
public int get(int key) {
return super.getOrDefault(key, -1);
}
public void put(int key, int value) {
super.put(key, value);
}
@Override
protected boolean removeEldestEntry(Map.Entry<Integer, Integer> eldest) {
return size() > capacity;
}
}
