最近在多看上看你了一本正则表达式的书《学习正则表达式》(英文:Introducing Regular Expressions), 让自己对正则表达式的特性有所了解,中文翻译主要是术语名词比较少见,本文会将术语都采用中英文。
本文主要是整理正则表达式的知识点,并且用Python写一些demo示例。正则表达式的特性很多, 不同的实现的特性有所差异,本文着重那些Python支持的特性。
什么是正则表达式?
“A regular expression is a pattern which specifies a set of strings of characters; it is said to match certain strings.”
—Ken Thompson
正则表达式是描述一组字符串特征的模式,用来匹配特定的字符串。
正则表达式出现在很多常用的linux工具中,常见的有:
- awk & sed
- grep & ack(类似grep但是更为强大,more)
- vim
一些正则表达式的在线工具,方便正则调试
- regex101: Online regex tester and debugger: JavaScript, Python, PHP, and PCRE
- RegExr v2.0
- Rubular: a Ruby regular expression editor and tester
- RegexPal 0.1.4: a JavaScript regular expression tester
基本模式匹配
字符串字面值(String Literal)
字符串字面值(String Literal),就是字面上是什么就是什么。
| 元字符(metacharacters)包括.^$*+? | (){}[]\-,在正则表达式中有特殊含义。 |
注意:对于元字符,使用其字面值需要进行转义。
import re
test_string = ('A regular expression is a pattern which specifies a set of strings of characters; '
'it is said to match certain strings.')
print re.findall(r'regular', test_string) # ['regular']
# 元字符的转义
print re.findall(r'strings\.', test_string) # ['strings.']
字符组(Character Classes)或字符集(Character Set)
字符组(Character Classes)或字符集(Character Set),用方括号来表示一组字符,例如:[0-9]、[a-z]。 字符组还可以进行取反的操作,例如:[\^0-9]表示匹配非数字的字符,与\D含义一致。
常见的字符简写(Character shorthands)
| 简写 | 描述 | Description |
|---|---|---|
| \a | 报警符 | Alert |
| [\b] | 退格字符 | Backspace character |
| \c x | 控制字符 | Control character |
| \t | 制表符 | Horizontal tab character |
| \r | 回车符 | Carriage return |
| \n | 换行符 | Newline character |
| \d | 数字字符 | Digit character |
| \D | 非数字字符 | Non-digit character |
| \o xxx | 字符的八进制值 | Octal value for a character |
| \w | 单词字符 | Word character |
| \W | 非单词字符 | Non-Word character |
| \s | 空白符 | Space character |
| \S | 非空白符 | Non-space character |
| \0 | 空字符 | Nul character |
| \x xx | 字符的十六进制值 | Hexadecimal value for a character |
| \u xxx | 字符的Unicode值 | Unicode value for a character |
import re
test_string = '''! " # $ % & ' ( ) * + , - . /
0 1 2 3 4 5 6 7 8 9
: ; < = > ? @
A B C D E F G H I J K L M N O P Q R S T U V W X Y Z
[ \ ] ^ _ `
a b c d e f g h i j k l m n o p q r s t u v w x y z
{ | } ~
'''
print re.findall(r'[0-9]', test_string) # ['0', '1', '2', '3', '4', '5', '6', '7', '8', '9']
print re.findall(r'\d', test_string) # ['0', '1', '2', '3', '4', '5', '6', '7', '8', '9']
print re.findall(r'[0-3]', test_string) # ['0', '1', '2', '3']
print re.findall(r'[a-z]', test_string)
# ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l', 'm', 'n', 'o',
# 'p', 'q', 'r', 's', 't', 'u', 'v', 'w', 'x', 'y', 'z']
边界(Boundaries)
断言(asserions)标记边界,但是并不消耗字符——也就是说字符不会返回在结果中。因此,断言也被 叫作零宽度断言(zero-width assertions)。
常见的边界有行起始^和行结尾$
边界简写
| 简写 | 描述 | Description |
|---|---|---|
| \b | 单词边界 | Word boundary |
| \B | 非单词边界 | Non-word boundary |
import re
test_string = 're great'
print re.findall(r're', test_string) # ['re', 're']
# 匹配单独的re
print re.findall(r'\bre\b', test_string) # ['re']
# 匹配great中的re
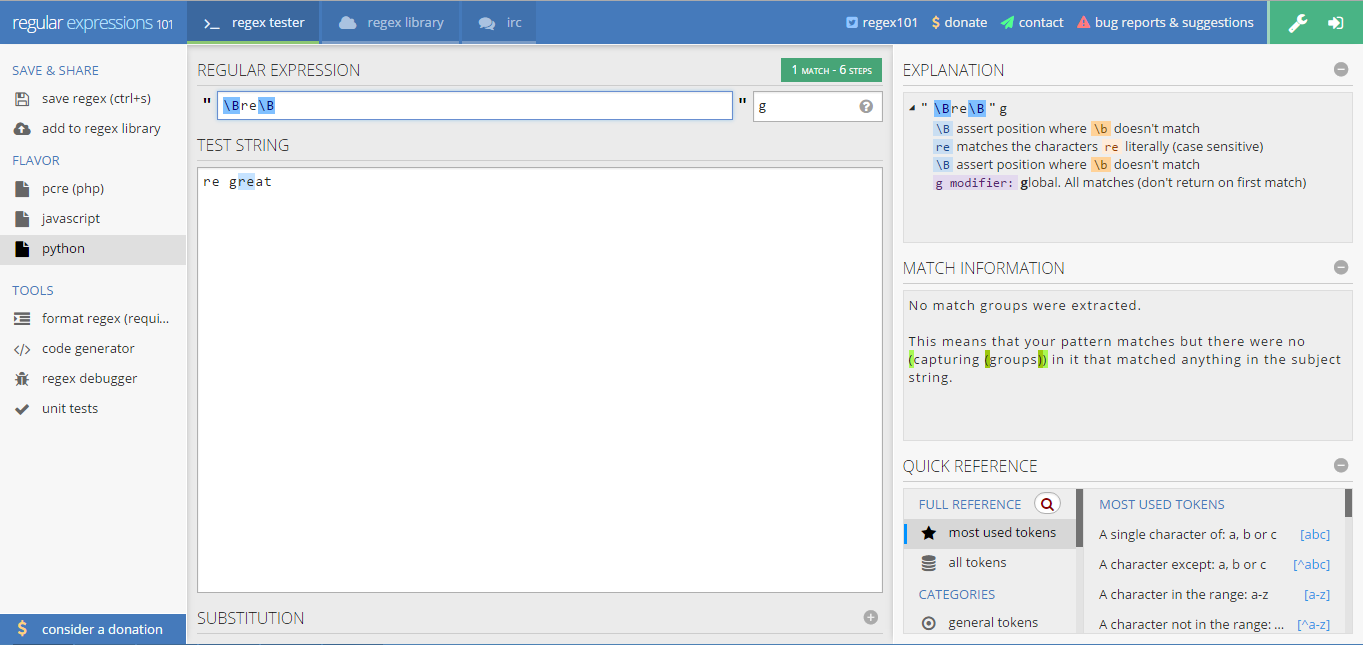
print re.findall(r'\Bre\B', test_string) # ['re']
在regex101进行测试’\Bre\B’
量词(Quantifier)
量词是用来修饰前面一个子模式的。
量词语法
| 语法 | 描述 | 等价 |
|---|---|---|
| ? | 零个或一个 | {0,1} |
| + | 一个或多个 | {1,} |
| * | 零个或多个 | {0,} |
| {m} | 精确匹配m次 | |
| {m,} | 匹配m次或大于m次 | |
| {m,n} | 匹配m到n次,包含m和n |
匹配任意字符的正则是.*,其中.匹配任意单个字符。
量词的贪婪(Greedy)、懒惰(Lazy)和占用(Possessive)
量词本身是贪婪的,会尽可能匹配多的内容。量词首次尝试匹配整个字符串,如果失败回退一个字符再次尝试,这个过程叫作回溯(backtracing)。 回溯本身是会影响正则表示式匹配的性能的。
懒惰的量词是另外一种策略,仅可能匹配少的内容,语法是在普通量词后加一个问号(?)。匹配方式是从起始位置开始尝试匹配, 每次检查一个字符,直到匹配整个字符串。
占用量词会覆盖整个目标然后尝试寻找匹配内容,只尝试一次,行为和贪心比较类似,但是不回溯。 语法是在普通量词后加一个加号(+),Python不支持这种语法。这种匹配方式是有助于提升性能的, 因为没有回溯。
import re
# 贪婪的量词
print re.match(r'\d{3}', '123456').group() # 123
print re.match(r'\d{3,6}', '123456').group() # 123456
print re.match(r'\d{3,6}678', '12345678').group() # 12345678
# 懒惰的量词
print re.match(r'\d{3,6}?', '123456').group() # 123
print re.match(r'\d{3,6}?678', '12345678').group() # 12345678
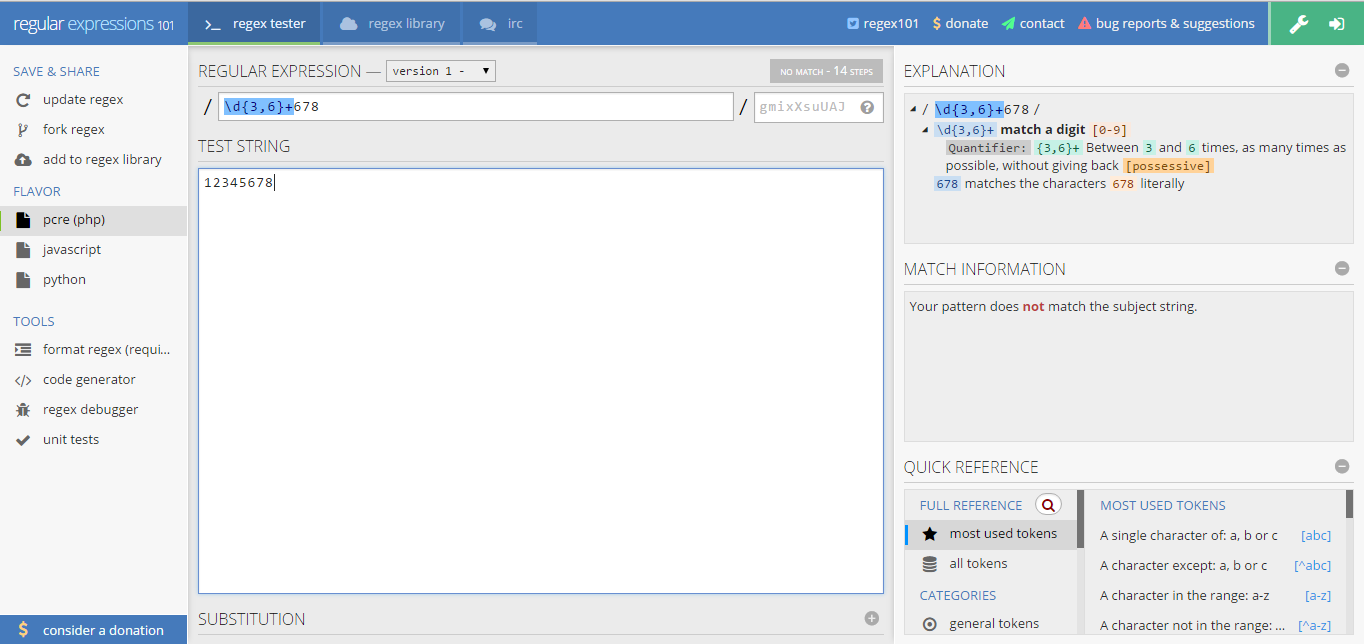
# 占用量词,python不支持,可以在regex101使用pcre(php)来测试
# print re.match(r'\d{3,6}+678', '12345678') # None
# 无法匹配成功,因为\d{3,6}+会直接匹配123456,后面只剩下78,并且不回溯,无法匹配剩下的678
占用量词在regex101
选择(Alteration)、分组(Groups)和反向引用(Backreferences)
| 选择操作是在多个可选模式中匹配一个,使用 | 操作符,可以用括号()或方括号[],两种括号略有区别,看后面的代码示例。 | |||
| 例如,匹配the和The可以使用(T | t)he,第一个字符(T | t)会匹配T或t;(T | t)he和[T | t]he是等价的。 |
(?i)表示忽略大小写,(?i)the可以匹配the, The, THE三种。
选项(只包含Python支持的选项)
| 选项 | 描述 |
|---|---|
| (?i) | 不区分大小写 |
| (?s) | 单行(dotall) |
| (?m) | 多行 |
| (?x) | 忽略空格和注释 |
捕获分组(Capturing Groups)是指模式中的全部或部分内容被一对括号选中的部分,会有一个或多个。 被捕获的分组会被保存在内存中,可以通过反向引用来重用捕获的内容,一般是在正则替换的操作中。 使用方法是通过\1来引用第一个捕获的分组,\2来引用第二个捕获的分组,以此类推。
分组默认的反向引用是靠序号来引用,也可以使用命名分组(named group),这样可以通过名字来进行引用。
语法:(?P<name>…)表示命名分组,(?P=name)表示引用命名分组。
**注意:re.sub方法的repl参数,使用/g
捕获分组是需要消耗内存,如果我们不需要引用分组的时候,就可以使用非捕获分组(Non-Capturing Group)。 语法是在分组的括号前面加上?:,例如:(?:pattern)。
Python不支持原子分组(atomic group),原子分组是不会回溯(backtracing)的。
import re
# (T|t)可以匹配多个模式,同时也是一个分组,会被捕获
print re.findall(r'(T|t)he', 'The the') # ['T', 't']
# 方括号也可以匹配多模式
print re.findall(r'[T|t]he', 'The the') # ['The', 'the']
# 非捕获分组
print re.findall(r'(?:T|t)he', 'The the') # ['The', 'the']
# 使用(?i)忽略大小写
print re.findall(r'(?i)the', 'the The THE') # ['the', 'The', 'THE']
# 替换
print re.sub(r'([\w! ]+)',
r'<h1>\1</h1>',
'Welcome to home!') # <h1>Welcome to home!</h1>
# \1和\g<1>等价
print re.sub(r'([\w! ]+)',
r'<h1>\g<1></h1>',
'Welcome to home!') # <h1>Welcome to home!</h1>
print re.sub(r'(world) (hello)',
r'\2 \1',
'world hello') # hello world
# 命名分组在sub中的引用
print re.sub(r'(?P<title>[\w! ]+)',
r'<h1>\g<title></h1>',
'Welcome to home!') # <h1>Welcome to home!</h1>
# 命名分组,忽略大小写匹配两个一样的单词
pattern = re.compile(r'(?P<a>(?i)\b\w+\b) (?P=a)')
print pattern.match('hello hello').group() # hello hello
print pattern.match('Hello hello').group() # Hello hello
高级匹配模式
高级特性包含:
- 量词的贪婪(Greedy)、懒惰(Lazy)和占用(Possessive)(注:在之前的量词部分已经讲解过了)
- 环视(Lookaround)
环视是现代正则表达式的一个重要特性。
环视(Lookaround)
环视是一种非捕获分组(Non-Capturing Group),也是零宽度断言(zero-width asserions), 是根据某个模式之前或之后的内容进行匹配。
环视包括:
- 正前瞻(Positive Lookaheads)
- 反前瞻(Negative Lookaheads)
- 正后顾(Positive Lookbehinds)
- 反后顾(Negative Lookbehinds)
命名的含义:正和反是指其是匹配还是不匹配;前瞻是指接下来匹配的字符,位于右侧;后顾是指之前匹配过的字符,位于左侧。
正前瞻(Positive Lookaheads)
要匹配某个模式,并且要求紧随其后的另一个模式,这个时候需要用到正前瞻,其语法是(?=…)。 例如:想匹配good,紧随其后的单词是job,即good job中的good,就需要用正前瞻,(good) (?=job)。
import re
print re.search(r'(good) (?=job)', 'good job').group() # good
print re.search(r'(good) (?=job)', 'good work') # None
print re.match(r'(good) (?=job)', 'good') # None
反前瞻(Negative Lookaheads)
反前瞻是对正前瞻的取反操作,即在匹配某个模式时,要求后面不匹配给定的前瞻模式。
import re
print re.match(r'(good) (?!job)', 'good job') # None
print re.match(r'(good) (?!job)', 'good work').group() # good
print re.match(r'(good) (?!job)', 'good') # None
# 匹配非连续出现的数字,\1 这种语法表示之前捕获的组
print re.match(r'(?:(\d)(?!\1))+', '3456').group() # 3456
print re.match(r'(?:(\d)(?!\1))+', '112233') # None
正后顾(Positive Lookbehinds)
正后顾是查看左边的内容,与前瞻的方向相仿,也就是之前匹配过的字符,因为是从左到右匹配,所以后顾的字符是在左边。
import re
print re.search(r'(?<=good) (job)', 'good job').group() # job
print re.search(r'(?<=good) (job)', 'a job') # None
print re.search(r'(?<=good) (job)', 'job') # None
反后顾(Negative Lookbehinds)
反后顾是正后顾的取反操作。
import re
print re.search(r'(?<!good) (job)', 'good job') # None
print re.search(r'(?<!good) (job)', 'a job').group() # job
print re.search(r'(?<!good) (job)', 'job') # None
